I wanted a clean way to read and listen to the Quran with multiple translations—without the bloated feel of existing apps. So I built QuranZen, now live at quranzen.com.
The core idea: keep the static Quran data local (SQLite), put user data in the cloud (Supabase).
Why two databases?
Most apps dump everything into one database. I split it based on how the data actually gets used.
- 6,236 ayahs across 114 surahs
- 20+ translations (English, Urdu, etc.)
- Audio metadata and word-level timing data (77k+ segments for word highlighting)
- Lives on the server, loads instantly
- Authentication
- Bookmarks, reading progress, completion tracking
- Row Level Security keeps users separated
- Syncs across devices
Quran data doesn't need to be in the cloud as it's reference material. SQLite means instant loads with no network overhead. User data needs cloud sync and auth, so Supabase handles that in it's free tier.
The stack
Frontend is React 19 with Vite 7 and React Router v7. Framer Motion for animations.
Backend is FastAPI. Quran endpoints hit SQLite (no auth required). User endpoints verify JWTs locally and talk to Supabase. Rate limiting via slowapi. Audio served directly from the backend so as to not put load on CDNs like Tarteel's.
What it does
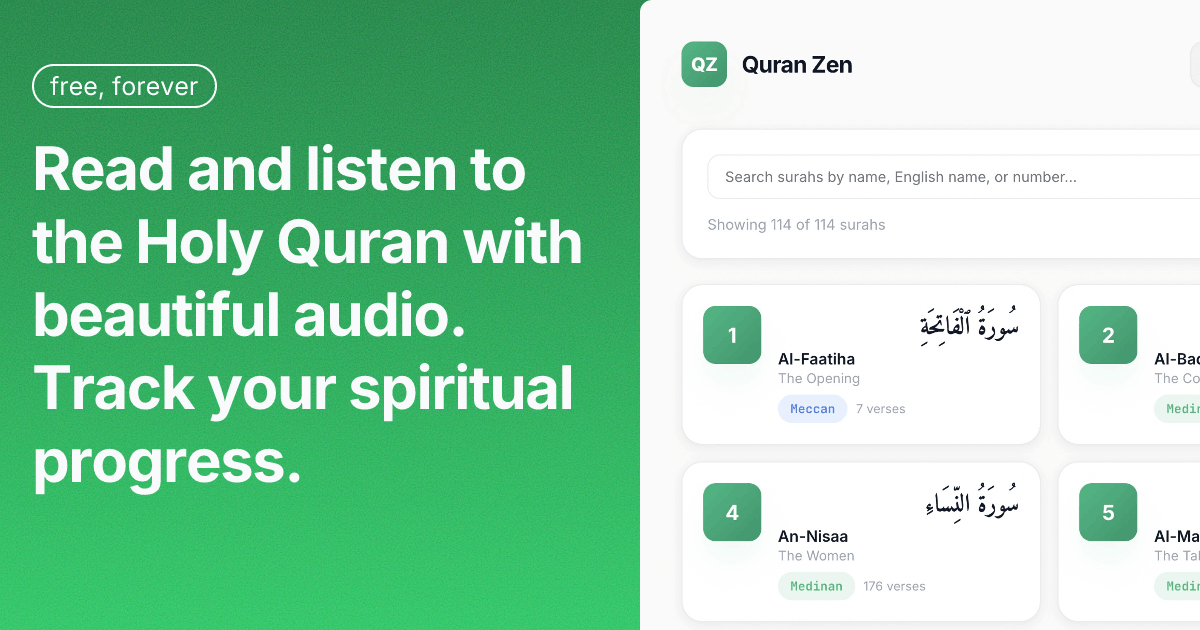
Reading
Fetch the surah list, pick one, get the ayahs. Browser caching makes subsequent reads instant. Multiple translations side-by-side. There's also word-by-word reading with Arabic-English breakdowns.
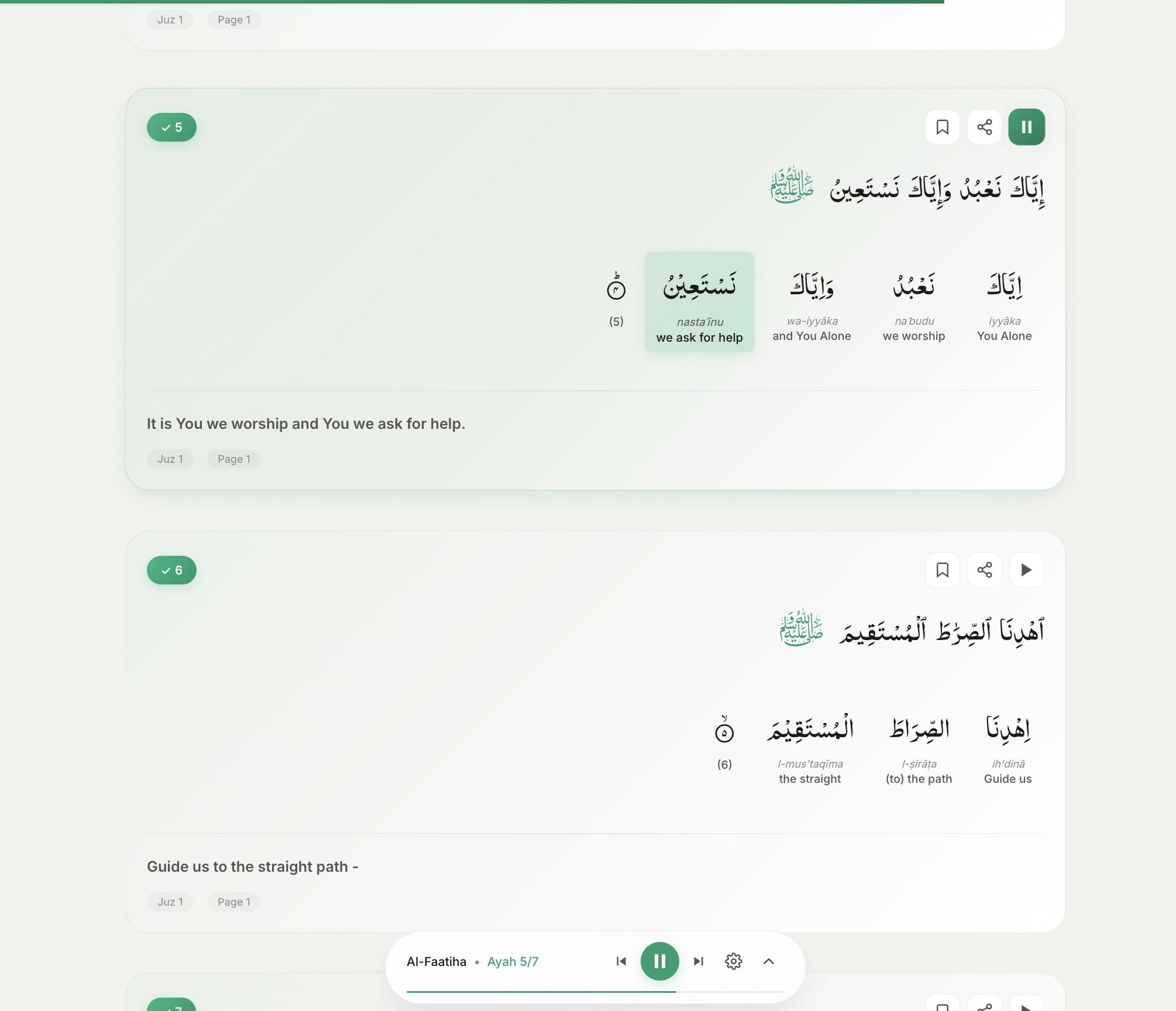
Audio
Pick a reciter (currently just Mishary Al-Afasy) and stream MP3s directly from the backend. The interesting bit is word highlighting—the app has timing data for every word, so it highlights each word as the reciter says it. No processing overhead, just static files plus timing metadata. Here's how I improved the segment timings using Whisperx.
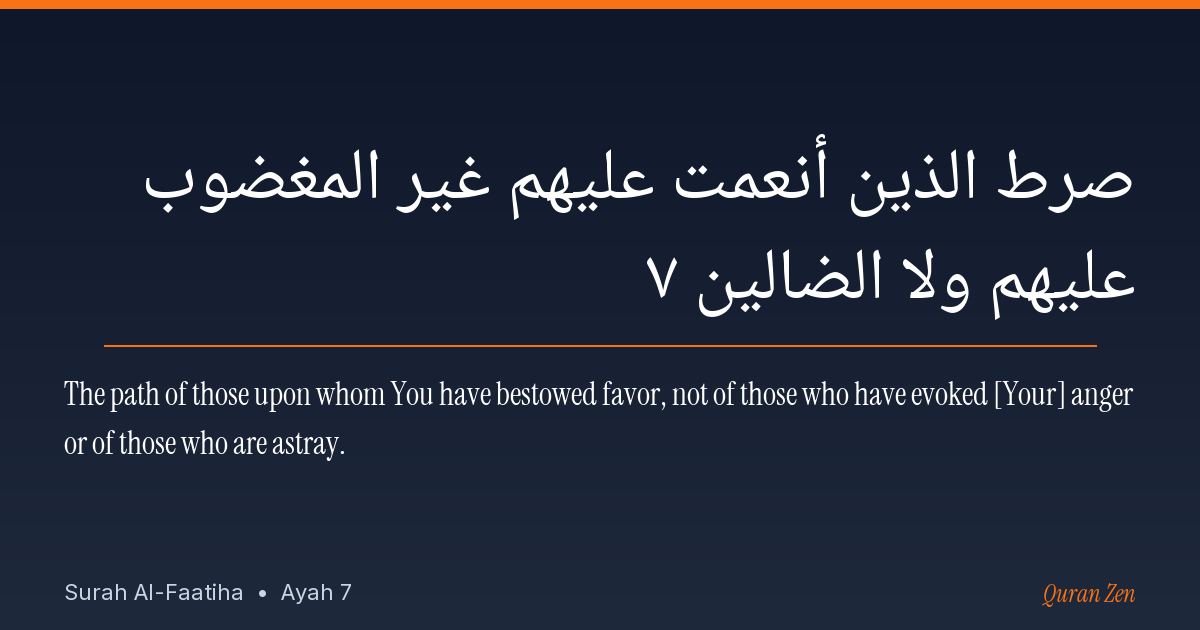
Sharing
Generate shareable ayah images with the Arabic text. Example:
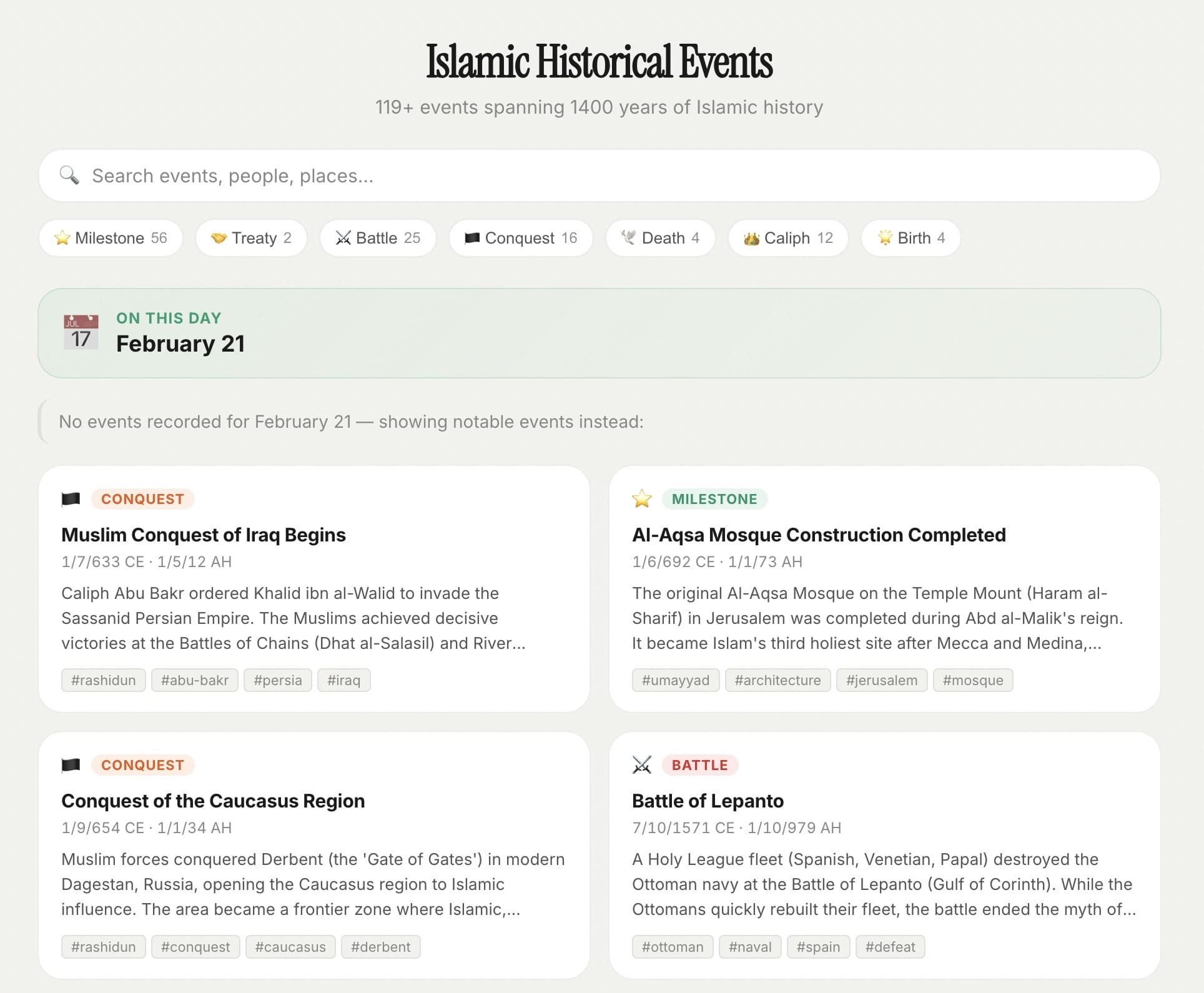
Islamic Events
A separate module that scrapes Wikipedia, uses NVIDIA NIM to extract structured event data, and stores it locally. You can browse events by date or category—stuff like "Battle of Badr occurred on 17 Ramadan."
Knowledge Articles
SEO-optimized content about Quranic topics. Generated via an LLM pipeline with fact-checking against the actual Quran text.
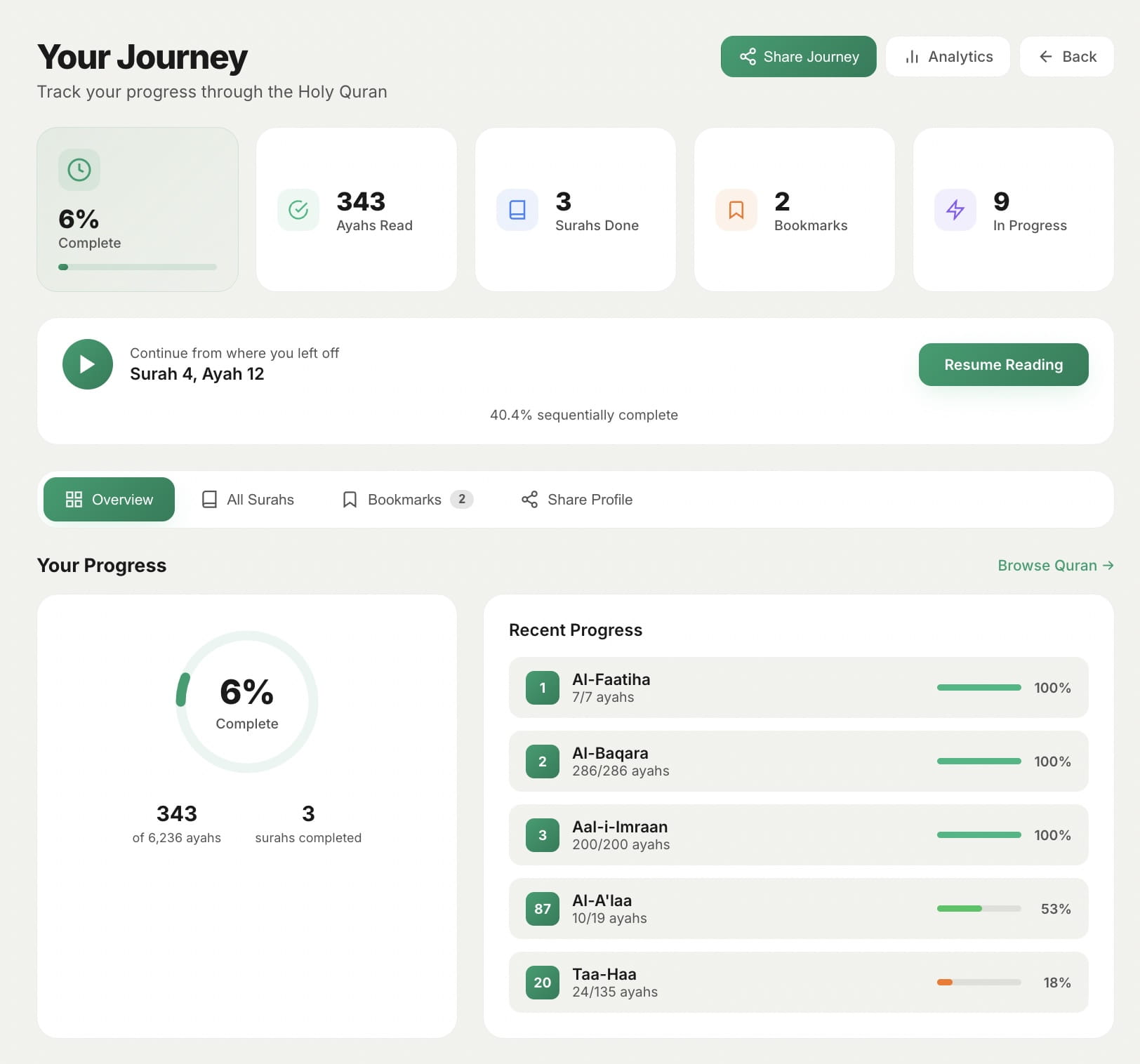
Reading Journey
Track your progress through the Quran. See which surahs you've completed and how much you've read over time.
Profile
Manage your account, view stats, and customize your reading preferences.
Deployment
Uses simple docker on a Netcup VPS with 4 AMD cores, 16GB RAM and a 1gbit connection (about £6.5/month)
What's still missing
No tests (#yolo #vibes) - i should add pytest for the backend and Vitest for the frontend.
If you're building an app with large static content plus small dynamic user data, this hybrid approach works. SQLite handles the heavy reads, Supabase handles the writes and auth. This way you get the best of both worlds.
Check out the live app